Serious Sam CS 175: Project in AI (in Minecraft)
Project Summary
Our hero Sam will fight with zombies in a 16x16 arena. The difference between our Sam and Sam who in the video game is that our Sam is using golden sword to fight. Sam is able to move and turn around to deal damage and try to kill all the zombies from all directions. Under 20 seconds limit, Sam will try to kill all the enemies while avoiding as less damage as possible.
Current situation video:
Approach
Deep Q Learning
-
Serious Sam, based on a game, will utilize deep reinforcement learning, specifically the Q-learning algorithm to make itself smarter. Though Q-learning on it’s own is a powerful algorithm, Serious Sam has a lot of different state-action pairs which make it easier to incorporate deep learning. Sam, our agent, starts off with a Q-network and a Target Network that each has one hidden layer and uses linear regression algorithm to calculate the Q-values. Sam will continue to update the Q-network until it either dies or the episode has maxed on the number of steps it can take.
-
Originally, Sam starts taking epsilon-greedy actions to ensure that Sam explores properly. As our epsilon value decreases, Sam starts to take actions that have a higher Q-value, that allows it to exploit higher reward actions more. Epsilon starts with a value of 1 and decreases by 0.999 each episode run.
-
The states are currated by the location of the agent and the location of the zombies. We would like the states to be currated by a multitude of factors such as location of the agent, location of the zombies, health of the agent,time left of the game and more. Therefore, using deep learning is perfect because there are too many states to actually keep track of every one. We did try to make the states dependent on the agent’s coordinate location, however, that wasn’t enough information for the agent as the Zombies and the agent are constantly moving to different places and the agent as a result would just attack at anytime. Currently, Sam can take four actions: move forward, turn left, turn right, or attack. The actions are chosen using a decreasing epsilon-greedy approach to balance exploration and exploitation of different state-action pairs.
-
To enforce that Sam tries harder to stay alive, the reward for dying is -1000. If Sam was able to attack a Zombie, it will receive +100. Lastly, if Sam was just running away and not killing the Zombies, causing the timer to run out, we gave it -10 points. We are still experimenting with the reward function, because Sam dies often, causing it too see positive reward less. For example, we are trying to add negative reward for every action taken, so Sam will learn to strategize and kill the Zombies faster.
-
To calculate the Q-values, the following update function is being used by Pytorch. Gamma is the discount factor, which will discount the rewards that are predicted to be achieved in the future. R(s,a) is the reward that was received at that state-action pair. Q-learning uses reinforcment learning’s temporal difference learning strategy to calculate the current state-action pair’s Q-value. By taking the difference between the current state-action pair’s Q-value and the maximum successor’s state-action pair’s Q-value, which initially starts off at 0 as the agent is exploring, the agent can adjust it’s decision making power. $Q(a,s) = R(s,a) + \gamma max_{a’}Q(s’,a’)-Q_{t-1}(s,a)$
-
For the next run, we would like to experiment with the deep learning aspect of this algorithm. Currently the Q-network only has one hidden layer inbetween, but if more are used the the agent will make more precise measurements on which action to take.
Evaluation
As of right now, we are evaluating Sam’s performance based on the average return after N episodes. We are doing so because, reward shows that the agent has been learning how to achieve that reward through certain decisions.
Qualitative:
-
Once we see our Serious Sam fighting off Zombies by timing his sword strikes and walking towards the Zombies
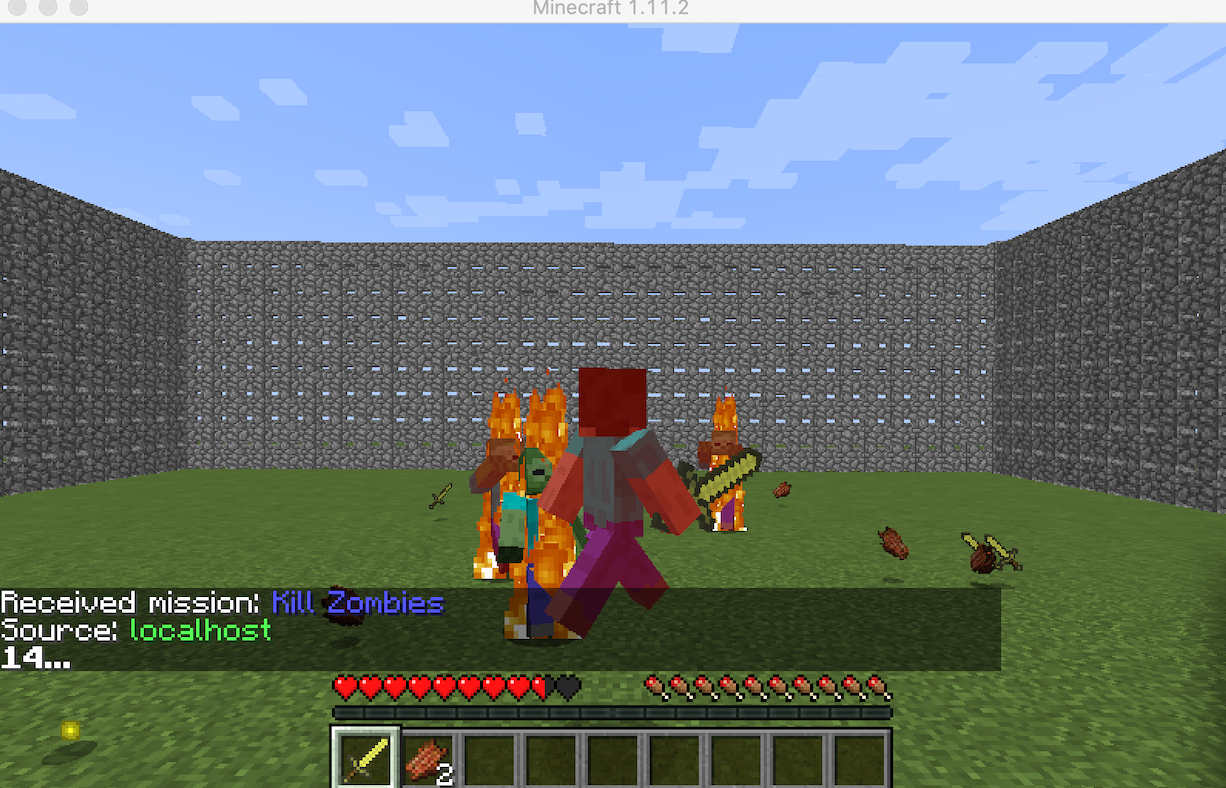
-
As shown in the image above, the agent, Sam, is surrounded by four Zombies and is taking some damage. This image is episode # 3, which is in the very early stages of it’s learning. This is an example of how early on,the agent would get crowded around by the zombies, and get overwhelmed with the constant damage.
Quantitative:
-
In terms of Quantitative results, we would like to see the graph of results on an upward trend as the steps go up. Currently, the results are not positive in correlation with the number of steps.
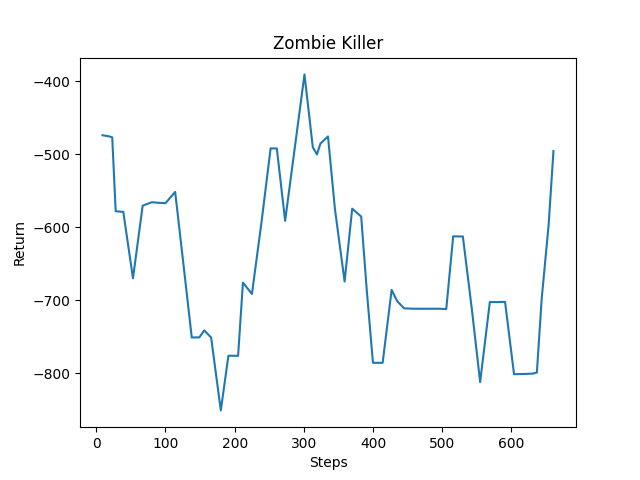
-
Right now, some missions fail to calculate the reward, causing some of the rewards of certain episodes to be off. As a result, the agent is picking up on wrong patterns and actions. We have tried to debug to find out what might be causing the error. We have recently found out that the error is caused by the client not understanding when the mission is completed. This is an issue that we need to resolve next.
-
Another thing to keep mind when looking at these results is that there were only around 750 steps taken, which was equivalent to about 60 episodes, which was is not much at all. The agent was mainly exploring between different states and actions, which usually results in it dying. The reason that the average returns as shown in the image above is constantly going up and down by big jumps is because of the issue mentioned above. The missions that didn’t register the returns would automatically return 0 which would make the returns between episodes oscillate between -1000 and 0. However, throughout time, the agent was slightly improving it’s reward even with the issue in place. Around step #250 and #650 the agent starting picking up the pace. Since the agent rarely attacked when the Zombie was in front of him, the agent’s reward stayed below 0, which is something it would learn over time.
Remaining Goals and Challenges
For the update version in the future, we expect our hero Sam will be able to move and turn around faster for dodging the attacks from the enemies. Moreover, Sam’s attacking timing is also need to be improved; so, Sam can deal more damage to kill enemies. the enemies will spawn randomly in the map. For answering this, we need to improve our Q table, angle and choosing target functions to make the situation better. For instance, which direction should the agent turn, which way has less enemies, avoiding to get knock back into walls or corners and attack faster and more accuracy. If we can do all of these above, maybe we can try different enemies like witches who can fly in the air; so, Sam should switch weapon like bow to shoot witches.
Resources Used
build_test.py, mob_fun.py, tabular_q_learning.py and moving_target_test.py from Canvas page.
https://eg.bucknell.edu/~cld028/courses/379-FA19/MalmoDocs/classmalmo_1_1_mission_spec-members.html
https://microsoft.github.io/malmo/0.17.0/Python_Examples/Tutorial.pdf
https://tsmatz.wordpress.com/2020/07/09/minerl-and-malmo-reinforcement-learning-in-minecraft/
https://github.com/microsoft/malmo/blob/master/Schemas/Types.xsd
https://microsoft.github.io/malmo/0.14.0/Schemas/Mission.html#element_Weather
https://towardsdatascience.com/simple-reinforcement-learning-q-learning-fcddc4b6fe56